-
[RxPy] CPU Concurrency와 Muliti Thread로 Rx하기💻 프로그래밍/Python 2020. 7. 14. 19:13
안녕하세요! 운동하는 개발자 JAY 입니다!
오늘은 드디어! RxPY를 Multi Thread(멀티 쓰레드)로 사용하는 방법에 대해 설명하려고 합니다!
직접 코드를 실행해보기에 앞서 몇 가지 개념에 대해서 알아보고 들어가겠습니다!
1. Concurrency(병행성) VS Parallelism(병렬성) 🌏
RxPy 3.1.0 문서에 보면 Multi Thread 관련된 설명에 이렇게 나와 있습니다.
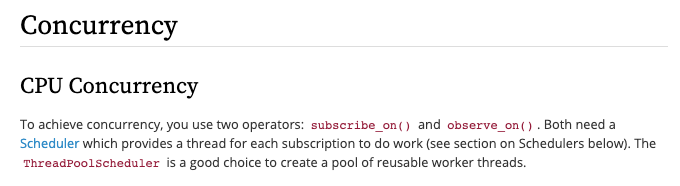
Concurrency (병행성) Concurrency(병행성)이라는 개념이 살짝 헷갈릴 수도 있는데, 보통 Multi Thread하면 Paralle(평행) 이라고 생각을 할 수 있는데, 다른 언어는 어떤지 모르겠지만 RxPy에서는 Concurrency(병행)입니다.
즉, 실제로 동시에 실행하는 것이 아닌 동시에 실행하는 것처럼 보이는 것입니다.
예를 들어,
- CPU 4개로 각각 프로그램을 동시(Parallelism)에 실행
- CPU 1개에서 쓰레드를 4개 만들어서 동시(Concurrency)에 실행하는 것처럼 보임그래서 RxPy에서 비동기는 Parallelism(병렬성)이 아닌 Concurrency(병행성) 입니다.
(참고. python에서 Multi Processs로 구현하여 따로 돌릴 수 있는 방법(multiprocessing)이 있기는 합니다.)
2. RxPy의 Multi Thread 🌈
RxPy에는 Multi Thread를 Scheduler라는 것으로 구현할 수 있습니다. 다양한 Scheduler가 있지만, 그중 몇 가지만 알아보겠습니다.
- CatchScheduler : 예외처리(exception)를 추가할 수 있는 Scheduler
- CurrentThreadScheduler : 현재 Thread에 있는 작업의 단위들을 스케줄 해주는 Scheduler
- EventLoopScheduler : 지정된 Thread에서 작업 단위를 스케줄 하는 오브젝트 생성해주는 Scheduler
- HistoricalScheduler : 절대 시간으로 datetime을 사용하고 상대 시간으로 timedelta를 사용하는 virtual Time Scheulder를 제공한다.
- ThreadPoolScheduler : Thread Pool을 통해서 작업을 실행하는 Scheduler
- ImmediateScheduler : 현재 Thread를 즉시 실행시키는 Scheduler. ImmediateScheduler를 사용하면 schedule timeouts을 사용할 경우 현재 스레드를 차단하기 때문에 schedule timeouts을 사용할 수 없다. (WillBlockException 발생)
- TimeoutScheduler : 시간을 예약해서 callback 받는 Scheduler
- NewThreadScheduler : 별도의 스레드에서 각 작업 단위를 예약하는 object를 생성하는 Scheduler
- TrampolineScheduler : trampoline의 작업 단위를 예약하는 object입니다. 대기 시간 동안 스레드를 차단하므로 TrampolineScheduler를 사용하여 시간 초과를 예약해서는 안된다. (trampoline 이란 현재 스레드에서 이전 작업 완료될 때까지 Queue에 대기시켜주는 작업(?))
- VirtualTimeScheduler : Virtual Time(가상시간) Scheduler를 생성합니다. 이 Scheduler는 datetime/timespan 또는 ticks(int/int)으로 실행되어야 합니다.
자세한 내용은 여기서 확인할 수 있습니다.
3. RxPy를 Concurrency(병행성)하게 사용하기 ✏️
자, 그럼 어느 정도 개념은 알았고, RxPy에서 어떻게 Multi Threading을 하는지 알아보겠습니다.
위에 이미지에서 봤듯이 RxPy에서 Multi Thraad를 사용하는 방법은 subscribe_on()과 observe_on()을 사용하여 구현할 수 있습니다. 여기에 추가로 subscribe()할 때, 파라미터로 default scheduler를 정해 줄 수 있습니다.
- subscribe_on() : subscribe(구독) 할 때 실행되는 Thread를 지정한다.(구독 시점에 사용) 여러 번 사용할 경우 한 번만 실행되며 나머지는 무시된다.
- observe_on() : pipe() 내부에서 사용하며, 각 연산자마다 새로운 Thread를 부여할 때 사용
- subscribe(scheduler=scheduler) : pipe() 내부에서 사용하는 모든 연산자에 대한 Default Thread를 지정할 때 사용,
먼저, 마블 맵으로 확인해 보겠습니다.

obeserve_on()과 subsribe_on() 마블맵 마블 맵에서 볼 수 있듯이, subscrbie_on()은 stream()의 첫 시작, 구독하자마자 실행되는scheduler(thread)입니다.
그리고 observe_on()은 subscribe_on()에 영향을 주지 않습니다.
각각의 예제를 코드로 한번 확인해보겠습니다.
📌 subscribe()의 default schduler로 실행되는 경우 (MainThread)
123456789101112131415161718192021222324252627282930313233from threading import current_threadfrom time import sleepfrom rx import range as rx_rangefrom rx.operators import observe_on, map, subscribe_on, do_actionfrom rx.scheduler import ThreadPoolSchedulersub_scheduler = ThreadPoolScheduler(1)test_range1 = rx_range(1, 5).pipe(do_action(on_next=lambda i: print("[debug] PROCESS 1: {0} {1}".format(current_thread().name, i))),observe_on(sub_scheduler),map(lambda x: 'pong' if x % 2 else 'ping'),do_action(on_next=lambda i: print("[debug] PROCESS 1: {0} {1}".format(current_thread().name, i))),).subscribe(on_error=lambda e: print(e),on_completed=lambda: print("PROCESS 1 done!"),)test_range2 = rx_range(1, 5).pipe(do_action(on_next=lambda i: print("[debug] PROCESS 1: {0} {1}".format(current_thread().name, i))),observe_on(sub_scheduler),map(lambda x: 'pong' if x % 2 else 'ping'),do_action(on_next=lambda i: print("[debug] PROCESS 1: {0} {1}".format(current_thread().name, i))),).subscribe(on_error=lambda e: print(e),on_completed=lambda: print("PROCESS 1 done!"),)sleep(1)sub_scheduler.executor.shutdown()간단하게 코드를 설명하자면, range() 연산자로 1~5를 순서대로 방출을 하게 되는데 정수가 방출될 때마다 map()을 실행해 홀, 짝 구분하여 ping, pong을 출력하게 됩니다.
(map() 연산자는 비교를 위해 observe_on()을 사용했습니다.)
do_action()은 유틸리티 연산자로서 on_next, on_error을 디버깅, 로깅용으로 사용하는 연산자입니다. on_next() 실행 시 현재 쓰레드가 뭔지 확인하기 위해 추가했습니다. shutdown()은 scheduler를 안전하게 종료하기 위한 함수입니다.
subscribe() 할 때 scheduler를 지정하지 않으면 MainThread에서 동작합니다. 한번 확인해 볼까요?
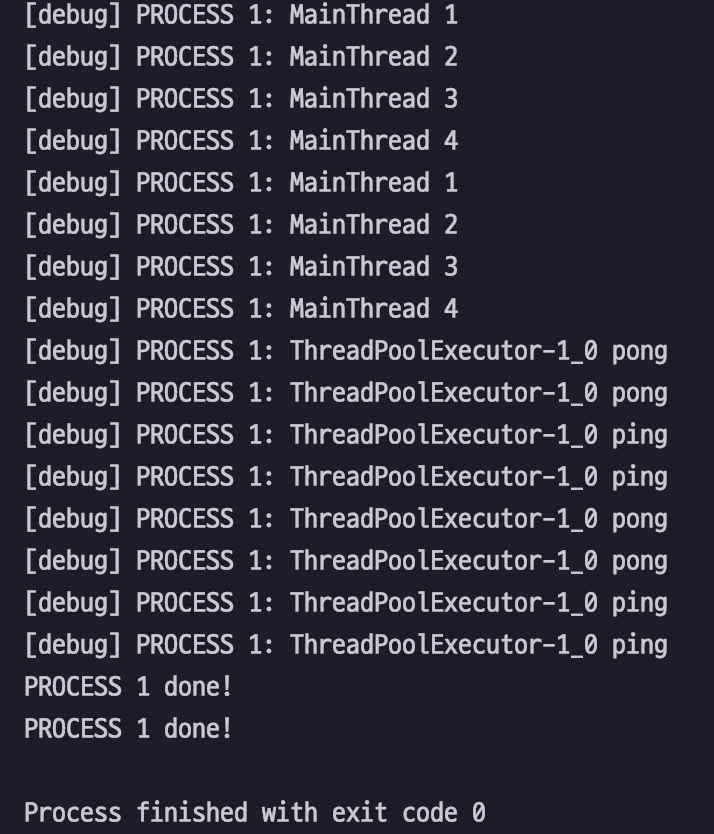
MainThread 에서 실행된 range() 오.. 일단 range()는 MainThread로 실행되었습니다.
한 가지 좀 다른 점은 MainThread로 방출되는 값은 1,2,3,4 ~ 1,2,3,4 이렇게 실행되고 sub_scheduler로 방출되는 값은 pong, pong -ping, ping ~ 이렇게 동시에 실행되었습니다!
현재 MainThread의 thread는 1개이고, subscribe() 할 경우 blocking 되어서 test_range1의 range()가 실행되고, 그다음 test_range2의 range()가 실행된 것입니다.
(subscribe()는 single-thread인 경우 현재 observable chain이 끝날 때까지 다른 observable은 blocking 된다. - 관련 내용)
map()의 경우 observe_on()으로 같은 Thread에서 실행되었고, blocking하지 않으므로 동시에 번갈아 가면서 방출된 것입니다.
📌 subscribe_on()으로 scheduluer를 정하는 경우
1234567891011121314151617181920212223242526272829303132333435from threading import current_threadfrom time import sleepfrom rx import range as rx_rangefrom rx.operators import observe_on, map, subscribe_on, do_actionfrom rx.scheduler import ThreadPoolSchedulermain_scheduler = ThreadPoolScheduler(1)sub_scheduler = ThreadPoolScheduler(1)test_range1 = rx_range(1, 5).pipe(do_action(on_next=lambda i: print("[debug] PROCESS 1: {0} {1}".format(current_thread().name, i))),observe_on(sub_scheduler),map(lambda x: 'pong' if x % 2 else 'ping'),do_action(on_next=lambda i: print("[debug] PROCESS 1: {0} {1}".format(current_thread().name, i))),subscribe_on(main_scheduler),).subscribe(on_error=lambda e: print(e),on_completed=lambda: print("PROCESS 1 done!"),)test_range2 = rx_range(1, 5).pipe(do_action(on_next=lambda i: print("[debug] PROCESS 1: {0} {1}".format(current_thread().name, i))),observe_on(sub_scheduler),map(lambda x: 'pong' if x % 2 else 'ping'),do_action(on_next=lambda i: print("[debug] PROCESS 1: {0} {1}".format(current_thread().name, i))),subscribe_on(main_scheduler),).subscribe(on_error=lambda e: print(e),on_completed=lambda: print("PROCESS 1 done!"),)sleep(1)main_scheduler.executor.shutdown()sub_scheduler.executor.shutdown()자 결과를 확인해 볼까요?
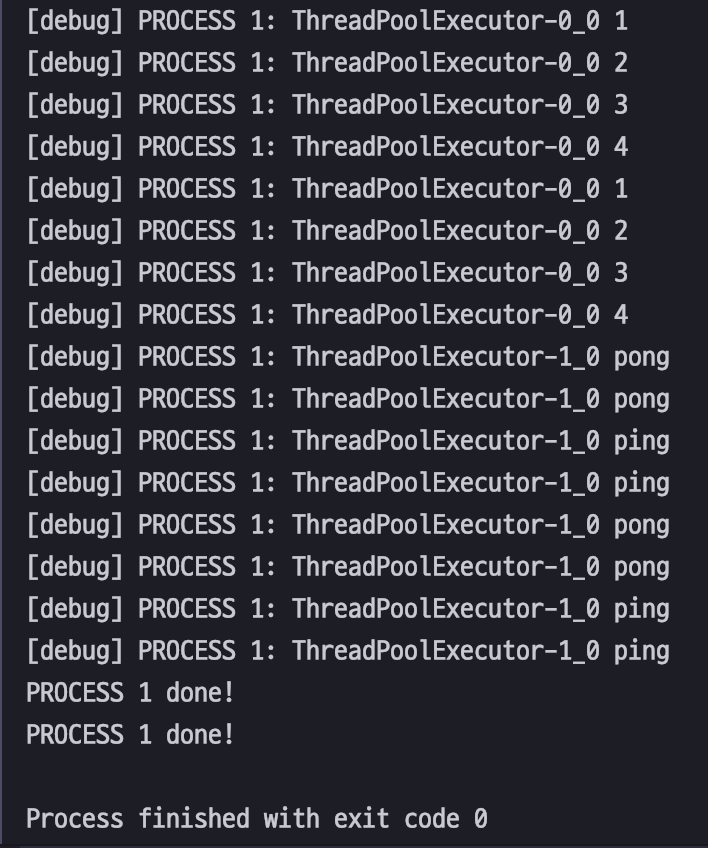
subscribe_on() 실행결과 오.. 일단 range()는 main_scheduler로 실행되었습니다.(Thread 이름을 보면 뒤에 -0, -1 다른 거 보이시죠?)
첫 번째 예제 코드의 결과와 실행 결과가 비슷하죠? 둘 다 subscribe(구독)하는 시점에 실행되는 연산자의 scheduler를 정해주기 때문입니다. (subscribe_on()은 위치는 상관없습니다. 어차피 구독하는 시점에 사용하기 때문!)
여기서 중요한 건 subscribe(구독)하는 시점이라는 것입니다! (ThreadPoolScheduler(n)의 Thread 개수가 증가하면 결과가 조금 다름)
그럼 여기서 subscribe()의 파라미터로 scheduler를 넣어줘도 똑같이 동작할까요?
📌 subsribe(scheduler=scheduler)으로 scheduler를 지정하는 경우
1234567891011121314151617181920212223242526272829303132333435from threading import current_threadfrom time import sleepfrom rx import range as rx_rangefrom rx.operators import observe_on, map, do_actionfrom rx.scheduler import ThreadPoolSchedulermain_scheduler = ThreadPoolScheduler(1)sub_scheduler = ThreadPoolScheduler(1)test_range1 = rx_range(1, 5).pipe(do_action(on_next=lambda i: print("[debug] PROCESS 1: {0} {1}".format(current_thread().name, i))),observe_on(sub_scheduler),map(lambda x: 'pong' if x % 2 else 'ping'),do_action(on_next=lambda i: print("[debug] PROCESS 1: {0} {1}".format(current_thread().name, i))),).subscribe(on_error=lambda e: print(e),on_completed=lambda: print("PROCESS 1 done!"),scheduler=main_scheduler)test_range2 = rx_range(1, 5).pipe(do_action(on_next=lambda i: print("[debug] PROCESS 1: {0} {1}".format(current_thread().name, i))),observe_on(sub_scheduler),map(lambda x: 'pong' if x % 2 else 'ping'),do_action(on_next=lambda i: print("[debug] PROCESS 1: {0} {1}".format(current_thread().name, i))),).subscribe(on_error=lambda e: print(e),on_completed=lambda: print("PROCESS 1 done!"),scheduler=main_scheduler)sleep(1)main_scheduler.executor.shutdown()sub_scheduler.executor.shutdown()달라진 건 main_scheduler를 subscribe()할 때 파라미터로 넣어준 것뿐입니다. 결과를 확인해보겠습니다!

subscribe() 파라미터로 sheduler를 선언 결과 오! 달라졌어요! 이거... 분명히 동작이 다릅니다!! ㅎㅎ (사실 제가 많이 헤매었던 부분)
왜 그런지 다음 예제 코드와 함께 확인해보겠습니다.
📌 observe_on()을 통해 처음 실행되는 range()의 scheduler를 지정하는 경우
1234567891011121314151617181920212223242526272829303132333435from threading import current_threadfrom time import sleepfrom rx import range as rx_rangefrom rx.operators import observe_on, map, do_actionfrom rx.scheduler import ThreadPoolSchedulermain_scheduler = ThreadPoolScheduler(1)sub_scheduler = ThreadPoolScheduler(1)test_range1 = rx_range(1, 5).pipe(observe_on(main_scheduler),do_action(on_next=lambda i: print("[debug] PROCESS 1: {0} {1}".format(current_thread().name, i))),observe_on(sub_scheduler),map(lambda x: 'pong' if x % 2 else 'ping'),do_action(on_next=lambda i: print("[debug] PROCESS 1: {0} {1}".format(current_thread().name, i))),).subscribe(on_error=lambda e: print(e),on_completed=lambda: print("PROCESS 1 done!"),)test_range2 = rx_range(1, 5).pipe(observe_on(main_scheduler),do_action(on_next=lambda i: print("[debug] PROCESS 1: {0} {1}".format(current_thread().name, i))),observe_on(sub_scheduler),map(lambda x: 'pong' if x % 2 else 'ping'),do_action(on_next=lambda i: print("[debug] PROCESS 1: {0} {1}".format(current_thread().name, i))),).subscribe(on_error=lambda e: print(e),on_completed=lambda: print("PROCESS 1 done!"),)sleep(1)main_scheduler.executor.shutdown()sub_scheduler.executor.shutdown()이번에는 모든 연산자들을 observe_on()으로 scheduler를 지정해줬습니다. 실행결과를 확인해 보겠습니다!

observe_on()으로 각 연산자의 scheduler를 지정해준 경우 오! 바로 앞에 subscribe()의 scheduler를 파라미터로 지정해준 것과 동일한 결과가 나왔습니다!! (신기방기)
혹시 감(🍊)이 오시나요 여러분?

출처 : ngmspg(빙글) 네! 그렇습니다 subscribe()에 파라미터로 scheduler를 지정해준 건 observe_on()과 같은(비슷한) 동작을 합니다!!
정확히는 subscribe()에서 scheduler를 지정하는 경우 pipe() 내의 모든 operators(연산자들)의 default scheduler를 지정해주는 것입니다. 이거 관련해서 엄청 찾다가 회사 동료가 아래 이슈를 찾아줬습니다.ㅜㅜ
https://github.com/ReactiveX/RxPY/issues/250
Using RxPy in current thread without any scheduler · Issue #250 · ReactiveX/RxPY
I have some experience working with RxJava and recently I've started project in RxPy. During writing tests I found something that looked like a bug and totally changed expected behavior of my a...
github.com

코멘트를 달아준 RxPy Collaborator 개발자 영어는 잘 모르니 대충 요약하면...ㅋㅋㅋ
subscribe_on()과 subcribe(scheduler=scheduler)는 같지 않다.
subscribe_on()은 구독하는 시점의 실행되는 로직의 스케줄러이고, subcribe(scheduler=scheduler)는 모든 operators(연산자들) chain에 defualt로 사용되는 스케줄러를 지원한다.네 그렇다고 하네요! ㅋㅋㅋ 처음에 이걸 몰라서 subscribe()과 subscribe_on()의 결과가 달라서 많이 헤매었습니다 ㅠㅠ 진짜 이거 찾아본다고 새벽까지 디버깅 찍어보고 하다가...ㅠㅠ (회사 동료에게 감사를🙏)
4. 마치며 💡
내용이 생각보다 길어졌는데, 좀 더 정확한 내용을 전달드리려고 나름 노력 많이 했습니다!
(혹시 잘못된 내용이 있다면 언제든지 댓글로 남겨주세요!)
Scheduler에 대해서는 다룰게 좀 더 있는데, 이 정도만 알아도 기본(?)은 한 것 같습니다! (아마도?) 더 많은 정보를 원하시면 RxPy 공식문서를 참고하시면 될 것 같아요!
저는 다음에 RxPy 마지막 포스팅인 디버깅, 오류 연산자로 찾아오겠습니다! 오늘도 즐거운 코딩 하시길 바랍니다!! 아디오스~👋
'💻 프로그래밍 > Python' 카테고리의 다른 글
filter() + lambda VS list comprehension (2) 2020.08.10 [RxPy] 디버깅, 오류 처리하기 (2) 2020.07.15 [RxPy] Operator 응용과 Custom Operator 만들기(feat. 메서드 체이닝(Method Chaning)) (0) 2020.06.29 [RxPy] Reactive Programming? Rx? 그게뭐야? (2) 2020.06.23 [BitBar] 오픈소스 플러그인 내맘대로 만들어보기 (Mac OS 메뉴바 플러그인) (0) 2020.06.14